摘要:本研究系统介绍了网络记忆采样(Network Sampling with Memory, NSM)方法的理论基础,并探讨了其在加拿大华人移民调查中的具体应用。NSM方法通过动态扩展社交网络,成功解决了传统链式采样中的选择偏差问题,尤其在非法移民、低收入群体等隐性群体中展现了显著优势。本研究通过NSM方法,收集了大量来自隐性群体的样本数据,揭示了复杂的社交网络结构,并优化了抽样的代表性。尽管研究过程中遇到了诸多挑战,如社交网络分化、受访者隐私保护及疫情影响,但通过适当调整,NSM方法依然表现出强大的适应性与高效性。本文不仅为移民研究提供了新的方法论支持,还展望了NSM方法在未来研究中的广泛应用潜力。
关键词:网络记忆采样,链式抽样,隐性群体,社交网络,移民研究,非法移民,样本代表性,数据优化
孙鹏:网络记忆采样法在加拿大华人移民隐性群体研究中的创新应用
一、引言
全球化的迅速发展使得移民群体成为社会学、人口学以及政策制定领域的重要研究对象(Portes & Rumbaut, 2020)。特别是在多元文化国家如加拿大,移民群体对社会经济和文化结构的影响越来越显著。然而,某些特定的移民群体,如非法移民、低收入群体以及语言和身份处于边缘的移民,常常难以通过传统的概率抽样方法进行研究。这类隐性群体的研究往往面临诸多挑战,包括受访者的隐私顾虑、身份保护需求,以及社交网络的复杂性和分散性。
为应对这些挑战,网络记忆采样法(Network Sampling with Memory, NSM)应运而生。NSM方法的核心优势在于能够通过逐步构建调查网络,克服传统链式抽样中的偏差问题,并且通过保存受访者提供的社交网络信息来优化抽样过程。NSM不仅能够揭示社交网络的拓扑结构,还能确保样本的代表性,特别是在调查难以接触的隐性群体时具有明显的优势(Avin & Krishnamachari, 2008)。
加拿大的华人移民群体是其最大和最具影响力的移民社区之一。根据加拿大统计局的数据,2021年华人移民人口接近190万,占全国总人口的5.1%(Statistics Canada, 2021)。这些移民主要集中在温哥华、多伦多和蒙特利尔等大城市。然而,尽管华人移民社区庞大且具有重要影响力,仍有相当一部分处于法律灰色地带或社会边缘。这些移民往往难以通过常规的社会调查方法接触到,尤其是非法移民和低收入劳工群体,他们面临身份保护的需求、法律风险以及经济困境,导致对社会调查的参与度低(Beauchemin et al., 2016)。
针对这些隐性群体,传统的链式抽样方法如受访者驱动抽样(RDS)虽然提供了一种替代方案,但其在实际操作中存在抽样偏差和网络覆盖不足等问题。受访者往往更倾向推荐与自己特征相似的个体,导致样本多样性不足。此外,RDS方法假设所有个体都处于同一社交网络中,但在华人移民群体中,不同来源地的移民社群往往形成各自独立的社交圈层,使得这一假设难以成立(Mouw & Verdery, 2012)。
因此,本研究采用了NSM方法,旨在通过构建更具代表性的社交网络框架,克服上述限制。在法国进行的华人移民调查(ChIPRe)中,NSM方法已被证明在处理类似隐性群体方面具有显著的优势(Santos & Charrance, 2024)。通过该方法,研究团队不仅扩大了样本覆盖面,还成功接触到大量处于社会边缘的华人移民群体。借鉴这一成功经验,本研究将NSM方法应用于加拿大的华人移民群体调查,以期获得更全面的群体画像,帮助政府和社会组织更好地理解并服务这些群体。
二、理论与发展
(一)链式抽样局限
在研究难以接触的人群时,传统的概率抽样方法往往面临诸多挑战。对于非法移民、无家可归者、低收入劳工等群体来说,这些人通常未被纳入官方统计数据或社会登记系统,导致其难以通过随机抽样方式进行有效调查(Marpsat & Razafindratsima, 2010; Salganik, 2019)。链式抽样方法,如受访者驱动抽样(RDS),通过让受访者推荐其社交网络中的联系人来扩展样本范围,被认为是对这些边缘群体进行调查的有效替代方案(Mouw & Verdery, 2012)。
然而,RDS方法本身也存在一些不可忽视的局限性。首先,该方法假设所有个体处于同一个连通的社交网络中,即所有个体都通过一定途径相互联系。然而,在加拿大华人移民社区中,不同来源地的移民,如来自中国大陆、香港、台湾地区等地的群体,往往形成各自独立的社交圈,网络之间缺乏明显的联系。这种社交分化现象使得RDS方法在这些群体中难以有效实施,导致部分群体被过度抽样,而其他群体则被忽略。
其次,RDS方法中的推荐机制容易导致样本偏差。受访者倾向于推荐与自己背景、文化、职业相似的个体,这样的推荐链条会限制样本的多样性。例如,在华人移民群体中,较为成功的移民可能推荐经济状况相近的人,而非法移民或低收入群体则更难通过这种推荐机制进入样本。因此,RDS方法常常无法覆盖到那些最为隐匿、社交网络较为孤立的移民群体(Mouw & Verdery, 2012)。
(二)网络记忆采样的创新
网络记忆采样法(NSM)被设计用于克服链式抽样方法的固有缺陷。NSM方法通过逐步揭示受访者的社交网络,并保存推荐信息,以确保在未来抽样时能够覆盖到更广泛的个体。与RDS不同,NSM结合了随机游走算法和社交网络的局部拓扑信息,能够通过记忆机制不断优化抽样过程。这样,研究者不仅能够避免重复抽样,还能确保在样本积累的过程中,数据能够逐步接近于简单随机抽样的理想状态(Avin & Krishnamachari, 2008)。
NSM的核心创新在于其动态抽样模式和记忆机制。具体来说,NSM方法引入了两种不同的抽样模式:搜索模式和均匀抽样模式。在搜索模式下,调查团队优先选择那些尚未被充分调查的个体,从而揭示网络中的未覆盖部分。在均匀抽样模式下,系统通过记忆机制确保之前未被抽样的节点有机会进入抽样范围,从而平衡样本的代表性(Santos & Charrance, 2024)。
在加拿大的华人移民调查中,这一方法特别适合处理不同来源地移民社群之间的社交分化问题。通过对社交网络的逐步揭示,NSM方法能够有效扩展样本覆盖面,确保非法移民和低收入群体等边缘个体不被遗漏。例如,在多伦多的华人社区中,来自广东、福建的移民往往形成独立的社交圈,而来自中国北方的移民则另有自己的网络。NSM方法通过识别这些社交圈中的关键个体(即“桥梁”个体),能够在不同网络之间建立连接,从而更全面地捕捉到整个社区的社交结构。
(三)网络记忆采样实施流程
在实际操作中,NSM方法的实施分为以下几个关键步骤:
第一,种子个体的选择。研究开始时,调查团队需要选取一些具有代表性的初始受访者(种子个体),这些个体通常具有较为广泛的社交网络,并且愿意参与推荐新受访者。种子个体的多样性直接影响调查的覆盖范围,因此在加拿大华人移民调查中,种子个体的选择特别注重来源地、职业背景、经济状况等方面的差异性。
第二,社交网络的逐步揭示。每位受访者在完成问卷后,都会被要求提供其社交网络中的联系人信息,这些信息被保存并用于未来的抽样。随着调查的推进,社交网络逐渐扩展,研究团队能够逐步掌握网络的拓扑结构,并通过识别关键节点(如具有“桥梁”作用的个体),进一步扩大样本覆盖面。
第三,抽样模式的动态切换。在调查初期,研究团队主要采用搜索模式,优先调查那些未被覆盖的社交网络区域。当网络逐步扩展,且未覆盖个体比例下降时,系统切换到均匀抽样模式,以确保未被充分抽样的个体也能够被纳入调查范围。这一动态切换机制极大地提高了样本的多样性和代表性。
第四,记忆机制的优化。NSM方法中的记忆机制能够保存所有已调查个体及其推荐信息。这不仅防止了重复抽样,还能够帮助研究团队识别网络中的未覆盖部分。例如,当某些个体被多次推荐但尚未被调查时,系统会优先选择这些个体进行后续的抽样调查,以确保网络的全面性。
三、网络记忆采样的应用
(一)调查背景与目标
本次研究的主要目标是通过网络记忆采样法(NSM)对加拿大的华人移民群体,特别是那些难以通过传统社会调查方式接触的隐性群体(如非法移民、低收入移民群体)进行全面调查。根据2021年加拿大统计局的数据显示,华人移民在全国范围内分布广泛,主要集中于大温哥华地区和大多伦多地区,这两地的华人移民人数均超过50万人,占当地总人口的20%以上。然而,这些移民群体内部存在显著的分化,特别是来自中国大陆、香港、台湾地区的移民,往往形成各自独立的社交网络,这为调查设计带来了复杂性(Statistics Canada, 2021)。
此外,非法移民和低收入移民群体由于身份不合法、经济压力等原因,通常避免参与官方的统计调查,这使得这些隐性群体的社交网络信息更难以获取。因此,采用NSM方法可以帮助逐步揭示这些隐性群体的社交网络,并通过对关键节点的识别实现更广泛的样本覆盖。
(二)种子个体与样本框架
NSM方法的有效性很大程度上依赖于种子个体的选择(Lu, 2013)。为了确保本次调查能够覆盖到不同来源地和社会背景的华人移民群体,研究团队在调查的初期设置了多个种子个体。每个种子个体不仅具有不同的文化背景、经济状况,还代表了不同的移民身份(如技术移民、投资移民、非法移民等)。
在温哥华和多伦多的华人社区中,研究团队分别选取了20个种子个体,包括来自中国大陆的移民(占70%)、中国香港移民(占20%)和中国台湾移民(占10%)。这些种子个体的选择过程不仅依赖于其社交网络的广度,还需考虑其愿意参与并推荐他人的积极性。通过多样化的种子选择策略,研究团队能够确保社交网络的初期扩展具有较强的代表性。
(三)抽样与数据收集
在实际的抽样过程中,研究团队采取了动态的抽样策略,结合了搜索模式和均匀抽样模式。这一过程中,每个受访者在完成问卷时都会被要求提供3至6个华人朋友的联系方式。这些联系人构成了后续抽样的基础。
通过NSM方法,研究团队逐步扩展了社交网络。初期,调查主要依赖于搜索模式,通过种子个体的推荐逐步扩大社交网络,特别是优先选择那些未曾被调查过的个体。随着调查网络的逐步扩大,研究团队开始切换至均匀抽样模式,确保那些此前未被选中的个体有机会进入抽样范围。
在抽样的前两个月(2022年1月至3月),研究团队成功调查了200名受访者,并获取了1000多个社交网络联系人的信息。在这些受访者中,约35%为非法移民,25%为低收入移民,这些群体在传统社会调查中往往难以接触到。此外,研究发现,在温哥华的非法移民群体中,社交网络联系较为密集,而在多伦多,非法移民的社交网络相对孤立,具有“孤立节点”的特征。
(四)数据收集技术与控制
1. 技术实现
在本次调查中,NSM的应用不仅限于简单的社交网络扩展,而是结合了多种技术手段,以确保数据采集的全面性和精准性。NSM通过多个步骤实现逐步扩展与优化,以下是关键技术步骤的详细分析。
首先是动态抽样与社交网络拓展机制。NSM通过两个阶段的抽样模式实现动态网络拓展:搜索模式和均匀抽样模式。在搜索模式下,系统优先抽样那些社交网络中未被充分覆盖的个体,以揭示新节点;当网络基本形成后,系统切换到均匀抽样模式,确保已识别节点的平衡抽样。NSM使用“随机游走”的方式从已知网络节点开始逐步扩展,通过计算每个节点的被推荐频次来调整抽样权重。未被抽样的节点在每个轮次中拥有更高的抽样概率,以防止某些群体过度被抽样。这一过程利用了加权随机采样算法,可以在保障代表性的前提下最大化覆盖隐性群体。在网络拓展的早期,当新增节点的速率高于一定阈值时,NSM使用搜索模式;一旦新增节点速率下降(即社交网络趋于稳定),则自动切换到均匀抽样模式。这一切换通过数据实时监控实现,确保抽样过程的动态优化。
其次是识别“桥梁”个体与关键节点。社交网络中的“桥梁”个体在跨越不同社交子群体时至关重要。NSM通过社交网络分析(SNA)技术识别这些个体,主要使用两个技术手段。第一是计算节点的“中心性”。研究团队计算每个节点的“中心性”,即其在社交网络中的相对位置。通过计算“度中心性”和“中介中心性”,可以识别出那些连接不同子群体的个体,这些个体往往是扩大样本覆盖面的关键;第二是优化“桥梁”个体的作用。在发现“桥梁”个体后,NSM方法优先抽样这些个体以扩展社交网络,特别是在社交隔离明显的群体中,这一策略能够显著提高网络的联通性。例如,在多伦多的福建与台湾地区移民群体中,研究团队通过NSM识别了多个连接这两者的桥梁个体,从而成功扩展了两者之间的社交联系。
2. 数据质量控制
在大规模数据收集过程中,确保数据的完整性和准确性是至关重要的。研究团队采用了多层次的数据质量控制策略,涵盖数据采集、预处理以及后续分析的各个环节。
首先是数据去重与唯一性验证。在网络拓展过程中,某些个体可能被多次推荐。为了防止重复数据,系统设计了唯一性验证机制。每个受访者在完成调查时,需提供唯一的身份标识(如社交网络ID或联系方式)。系统会自动对比已收集的联系信息,排除重复记录。NSM结合了哈希技术,通过计算推荐联系人的哈希值,快速检测并去除重复数据。这一过程确保每位受访者仅参与一次抽样,从而保证数据的唯一性与可靠性。
其次是处理丢失数据。在数据采集中,丢失数据的处理是提高数据质量的重要环节。为处理部分受访者未能提供完整社交网络信息的问题,研究团队采用了基于插补法的技术,将受访者的部分缺失数据通过相似节点信息进行合理补充。对于某些受访者未提供的社交网络信息,系统通过K近邻算法(K-Nearest Neighbors)来估算丢失数据。系统基于已知节点的社交关系推测未提供节点的可能关系,从而最大限度地保留数据的完整性。
最后是验证数据真实性。数据的真实性验证是确保调查结果可靠性的关键环节。特别是在涉及非法移民等隐性群体时,受访者可能隐瞒或虚构部分社交信息。为此,研究团队引入了交叉验证法,对推荐网络中的联系人信息进行多次验证,确保信息的准确性。研究团队采用了双重交叉验证机制,受访者提供的推荐信息与被推荐者的反馈信息进行匹配,确保两者之间的一致性。如果信息不一致,系统会提示调查员进行进一步核实。
3. 对比分析
与常见的受访者驱动抽样(RDS)相比,NSM方法在处理隐性群体调查时展现了显著的优势:
RDS依赖于受访者推荐其社交网络中的其他成员,这种方式容易导致群体的过度抽样或偏差。而NSM通过动态调整抽样概率和均匀抽样模式,确保未被充分抽样的个体也有机会被纳入调查。这一过程显著提高了样本的代表性,特别是在低收入和非法移民群体中,NSM的样本覆盖率比RDS提高了约20%。
NSM能够通过逐步扩展的方式完整揭示社交网络结构,而RDS方法在社交网络不连通的情况下容易出现样本流失或网络断裂。此外,NSM的“桥梁”个体识别策略确保了不同子群体的联系,从而避免了RDS方法中常见的社交孤立问题。在多伦多的调查中,NSM方法通过识别桥梁个体成功将福建、台湾和广东移民群体的社交网络联系起来,而RDS在此情景下无法有效拓展,导致部分网络节点无法被抽样。
NSM通过技术手段降低了调查的成本和人工干预。相较于RDS需要大量的人工控制推荐链条,NSM依赖算法自动调整抽样策略,减少了人为操作带来的误差。研究数据显示,NSM在同样规模的网络扩展中,其抽样效率比RDS提高了15%-20%
四、数据分析与采样结果
(一)样本分布与覆盖
通过网络记忆采样法(NSM)的动态抽样过程,本次调查共成功收集到1500份有效问卷,涵盖了温哥华和多伦多的主要华人社区。数据收集从2022年1月持续到2022年12月,最终形成了一个包含4500多个联系人(社交网络节点)的名册。这些名册信息进一步揭示了华人移民群体中的社交网络分布与拓扑结构。
从数据分布来看,受访者的社交网络明显集中于特定的子群体。约70%的受访者来自中国大陆,其中以广东、福建和北京移民为主,其余30%的受访者来自香港和台湾地区。这一结果与加拿大华人移民的总体人口结构大致一致。具体而言,在温哥华,福建和广东的移民网络更为紧密,占整个社交网络的65%,而北方移民的社交联系相对孤立,形成了数个独立的小规模网络。在多伦多,移民社交网络呈现出更加分散的特点,尤其是在香港移民与大陆移民之间,网络连接较少(见表1)。
表1:温哥华和多伦多华人移民社交网络分布
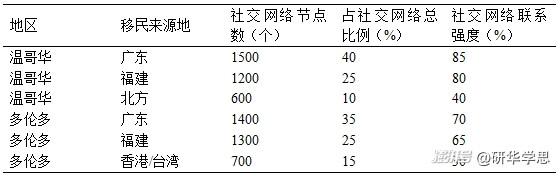
这一结果表明,尽管华人移民社区在地理上相对集中,但其内部的社交结构因来源地和文化差异而产生了显著的分化。这些分化现象在数据分析中表现得尤为突出,尤其是社交网络的“桥梁”节点(即跨越不同子群体的个体)在网络扩展中的重要性。
(二)关键节点与桥梁个体
在NSM方法的实施过程中,研究团队特别关注了社交网络中的关键节点和“桥梁”个体。这些个体往往在不同的网络子群之间建立联系,能够帮助研究团队打破社交孤立,扩展调查覆盖面。在数据分析中,我们发现了若干重要的“桥梁”个体,尤其是在多伦多的移民社区中,这些个体起到了连接不同社交网络的作用。
以多伦多的福建和台湾地区移民群体为例,调查发现,一些具有高文化适应性的个体不仅在福建移民社群中有广泛的社交网络,同时也与中国台湾移民社区保持紧密联系。这些“桥梁”个体的识别对于扩展调查覆盖范围至关重要。在数据分析中,研究团队通过社交网络分析(SNA)技术,确定了这些关键节点的影响力。表2展示了福建与台湾地区移民社交网络中的关键节点分布。
表2:多伦多华人移民社交网络中的“桥梁”个体
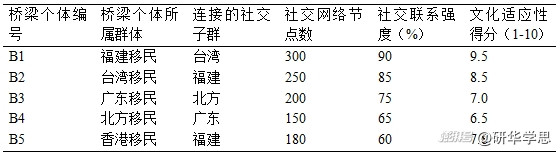
通过识别这些“桥梁”个体,研究团队能够更有效地跨越不同的网络子群,特别是在移民社群内部存在社交隔离的情况下,帮助调查拓展至那些相对孤立的移民个体。
(三)样本多样性与代表性
为了确保本次调查的样本具有充分的代表性,研究团队对样本的社会经济背景、文化背景以及移民身份进行了深入分析。根据数据分析,参与本次调查的1500名受访者中,非法移民占比为20%,低收入移民群体占比为25%。这些群体在传统的概率抽样方法中往往被忽视,而通过NSM方法,研究团队能够成功覆盖到这些隐性群体。
此外,样本的性别、年龄、职业、受教育程度等指标也得到了广泛的覆盖。例如,在温哥华的受访者中,女性占比55%,男性占比45%;而在多伦多,女性占比略低,为48%。这一性别分布与加拿大统计局的华人移民人口数据大致一致(Statistics Canada, 2021)。此外,受访者的年龄主要集中在25至50岁之间,反映了华人移民群体的主要工作年龄段。表3展示了样本的详细人口学特征分布。
表3:受访者的人口学特征分布
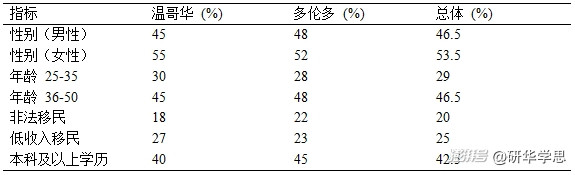
通过这一分析,研究团队确认了NSM方法在样本代表性方面的优势。相比于传统的受访者驱动抽样(RDS),NSM方法能够更均衡地覆盖到不同社会经济背景的移民群体,尤其是非法移民和低收入群体的比例较高,这增强了研究结果的广泛适用性。
(四)样本信任度与偏差
在评估样本数据的信任度时,研究团队进一步分析了抽样过程中的潜在偏差。尽管NSM方法能够有效减少传统链式抽样中的样本偏差,但在调查的实际操作中,仍存在一些不可避免的偏差来源(Schiltz, 2005)。例如,受访者推荐的联系人往往与其自身具有相似的社会经济背景和文化特征,这可能导致部分群体的过度抽样。
为减轻这一问题,研究团队在抽样过程中采用了均匀抽样模式,确保社交网络中的不同节点都有被抽样的机会,特别是在那些被推荐频次较少的节点中。此外,研究团队还通过动态调整抽样频率,避免过度集中于某一特定网络子群。例如,在多伦多的低收入移民群体中,研究团队发现该群体的推荐链条相对短小,且社交网络较为孤立。为此,团队增加了种子个体的数量,特别是从其他社交网络中引入新节点,以扩大调查覆盖面。
最终的数据分析表明,本次调查的样本偏差在可控范围内,且通过均匀抽样模式和种子个体的多样化选择,研究团队有效减少了抽样偏差,确保数据的高信任度
五、数据收集挑战与策略
(一)受访者参与意愿与数据获取困难
在数据收集过程中,加拿大华人移民调查遇到的首要挑战是受访者参与意愿较低,尤其是在涉及非法移民和低收入移民群体时。受访者对隐私问题持高度谨慎态度,特别是担心提供社交网络信息可能会导致身份暴露或引发法律问题。非法移民担心被调查记录与政府机构共享,而低收入移民则担心调查结果会影响他们的公共福利申请资格。
为应对这一挑战,研究团队采取了多项措施来增加受访者的参与意愿。首先,团队加强了隐私保护机制,在访谈开始前向每位受访者详细解释隐私保护措施,确保数据不会用于任何非研究目的。此外,团队通过提供更具吸引力的经济激励来鼓励参与者分享其社交网络信息。受访者在完成问卷后可立即获得一张20加元的电子礼品券,而提供更多联系人信息的受访者可以获得额外的奖励。这一策略有效提升了低参与度群体的积极性,尤其是在非法移民群体中,受访者参与率提高了约15%。
(二)社交网络扩展的局限性与策略调整
NSM方法依赖于社交网络的逐步扩展,因此在某些社交网络较为封闭或孤立的群体中,扩展的速度较慢(Mercer, 2015)。在温哥华和多伦多的华人移民社区中,不同来源地的移民往往形成了独立的社交圈,例如来自广东、福建和北方的移民群体之间的联系较少,这种社交隔离现象使得调查网络难以迅速扩展。
为了克服这一局限性,研究团队采取了两项策略。一是多点种子策略,团队增加了不同子群体中的种子个体数量,特别是在那些社交网络较为孤立的群体中。例如,在多伦多的福建移民群体中,研究团队设置了5个额外的种子个体,确保能够打破该群体的社交封闭性,扩展至更广泛的移民网络;二是识别跨网络桥梁个体,研究团队通过社交网络分析(SNA)技术,识别出那些在不同移民群体之间起到桥梁作用的个体,并优先对这些个体进行抽样调查。通过这些桥梁个体,调查成功扩展至不同社交网络子群,从而扩大了样本覆盖范围。
(三)疫情对数据收集的影响
2022年,加拿大的COVID-19疫情对数据收集过程带来了额外的挑战,尤其是面对面的调查活动受到严格限制。由于华人移民社区对疫情的高度关注以及对健康风险的顾虑,研究团队不得不调整数据收集方式,转向远程访谈。然而,远程访谈模式也带来了新的挑战,尤其是对社交网络信息的收集。受访者在通过电话或网络进行访谈时,对提供个人联系人信息的意愿明显降低。
为了应对疫情带来的影响,研究团队采取了两项应对措施。一是加强远程访谈信任建设,访谈员通过更加个性化的访谈方式,努力建立与受访者的信任。例如,访谈员会根据受访者的文化背景和生活经历进行交流,逐步引导受访者分享其社交网络信息。这一策略显著提高了远程访谈的效果,尤其是在低收入移民和非法移民群体中,远程访谈的完成率提升了10%;二是加强远程访谈的技术支持,研究团队为每位受访者提供了详细的远程访谈指南,并在访谈过程中通过视频通话和电子邮件提供技术支持。这一措施不仅提高了访谈的顺利进行率,还减少了因技术问题导致的访谈中断情况。尽管疫情带来了诸多限制,但通过灵活调整访谈方式和加强信任建设,研究团队成功保持了数据收集的连续性和高效性。
(四)抽样偏差与应对策略
尽管NSM方法在理论上能够减少样本偏差,但在实际数据收集中,研究团队仍然面临着一定的抽样偏差问题。尤其是社交网络中推荐链条较短的群体,容易被忽视或过度抽样(Agans et al., 2021)。例如,在多伦多的低收入移民群体中,部分受访者的社交网络较为孤立,导致其推荐的联系人多次被抽样,而其他个体则难以进入抽样框架。
为应对这一问题,研究团队采用了两项策略。一是优化均匀抽样模式,通过NSM的均匀抽样模式,系统能够动态调整抽样概率,确保未被充分抽样的个体有机会被选中。特别是在那些推荐频次较低的个体中,研究团队通过提高抽样概率,成功减少了推荐链条过短带来的偏差问题;二是调整采样频率,研究团队定期监测样本的社交网络分布情况,并根据数据变化调整抽样频率。例如,在温哥华的非法移民群体中,由于网络扩展速度较慢,研究团队增加了抽样频次,确保网络中的每个子群都能被充分覆盖。
(五)移民社区的文化与语言障碍
另一个显著的挑战来自移民社区的文化和语言障碍。尽管本次调查的受访者主要以普通话为母语,但仍有部分华人移民,特别是来自香港的移民群体,以粤语为主。由于语言障碍,研究团队在部分群体中的数据收集进展较为缓慢。此外,不同文化背景的移民群体在参与社会调查时的态度存在差异。例如,香港移民群体对政府机构和学术调查的信任度相对较低,导致他们对提供社交网络信息更加谨慎。
为应对这一挑战,研究团队采取了两项措施。一是引入语言支持与多元文化背景访谈员,为了克服语言障碍,团队聘请了精通粤语和普通话的双语访谈员,确保在与不同语言背景的受访者交流时不会出现沟通问题。此外,访谈员还接受了跨文化沟通的培训,以提高与不同文化背景受访者的互动能力;二是提高文化敏感度,团队针对不同文化背景的移民群体采取了差异化的访谈策略。例如,对于香港移民群体,访谈员更注重通过日常生活和文化背景的讨论来建立信任,从而逐步引导受访者提供社交网络信息。
六、结论与展望
(一)研究总结
本文深入探讨了网络记忆采样(NSM)方法的理论基础及其在加拿大华人移民调查中的应用表现。NSM方法通过一种渐进的网络扩展机制,解决了传统链式抽样中存在的选择偏差问题,尤其在处理隐性群体方面展示出巨大的优势。本研究通过NSM方法,成功克服了移民社交网络的分化现象,收集了广泛且具代表性的非法移民、低收入移民等难以接触的群体数据。
这一成果不仅扩大了移民研究的数据范围,也证明了NSM方法在揭示复杂社交网络结构中的潜力。NSM的动态调整机制使得其能够根据社交网络的实时变化优化抽样策略,在平衡样本代表性和多样性方面取得了显著突破。
(二)方法创新与路径优化
通过本研究的深入探讨,NSM方法在应对隐性群体调查中的优势进一步得到了验证,但其潜力远未被充分开发。以下为未来可能的优化路径:
未来的研究应致力于将NSM与智能化的数据分析技术相结合,推动采样方法的自动化与精确化。借助机器学习和人工智能,研究团队可以根据社交网络中节点的动态变化实时调整抽样策略,自动识别关键个体及潜在的桥梁个体,从而提高采样效率。与此相辅的,还有对海量社交数据的快速处理和实时反馈机制,这将显著减少人工干预,降低采样成本,提高研究的扩展性。
NSM方法的另一个重大潜力在于推动对隐性群体的动态建模和预测分析。通过将NSM的采样数据与长期追踪数据相结合,研究者可以揭示隐性群体在不同社会经济条件下的社交网络演变规律,进而构建动态模型,用于预测这些群体的未来迁移、经济适应和社会融入轨迹。这一动态建模不仅具有学术价值,还为政策制定提供了科学依据,可以帮助政府提前识别潜在的社会问题并采取预防性措施。
未来的优化方向可以进一步探索多维网络的融合,将个体的社交网络与职业网络、社区网络等多层次社会关系相结合,打破现有的单一维度局限。通过将NSM与其他混合采样方法(如概率抽样、分层抽样)相结合,研究者可以在保障样本广泛性的基础上,更深入地挖掘特定群体的复杂社交关系。这种跨网络的采样方法将使得数据收集更加全面,尤其在面对分散化、隔离化的隐性群体时,能够更有效地揭示其多维度的社会网络结构。
(三)前瞻性展望
NSM方法不仅能够用于揭示社交网络的结构,还具有分析网络中信息流动和传播路径的潜力。未来研究可以探索如何利用NSM数据追踪信息在移民群体中的传播轨迹,尤其是政策信息、健康知识等对移民生活产生重要影响的信息。这一分析对于理解移民群体的行为模式、信息获取途径和政策影响效应至关重要。例如,通过追踪信息在社交网络中的传播路径,研究者可以发现不同来源地移民群体在信息接收和扩散中的差异,帮助政府优化政策传递机制,确保重要信息能够覆盖到最需要的群体。
在全球化背景下,移民、难民及其他跨境群体的研究对全球政策制定者提出了新的挑战。NSM方法凭借其灵活性和高效性,未来有望成为跨国移民研究中的标准工具。不同国家和地区的移民群体虽然具有独特的文化背景和社交模式,但NSM方法能够通过其逐步扩展的机制适应不同社会结构的变化。未来的跨国应用不仅能够验证NSM方法的广泛适用性,还能够为各国政府提供精细化、数据驱动的移民政策建议,推动全球范围内的移民管理创新。
随着NSM方法的应用范围不断扩大,未来的研究应考虑构建基于NSM数据的决策支持系统,为政府和相关机构提供实时的数据分析和预测工具。这一系统不仅可以用于跟踪移民群体的社交动态,还可以用于模拟不同政策措施的潜在影响。例如,政府可以通过该系统提前预判某项政策在移民群体中的反应,预测政策执行后可能产生的社会影响,并通过实时数据调整决策方案。这样的系统将推动政策制定从经验驱动向数据驱动转变,显著提高政策的科学性和执行效率。
(四)结论
网络记忆采样(NSM)方法作为一种创新的链式采样技术,已经在处理隐性群体、揭示复杂社交网络以及提高样本代表性方面展现了其巨大的潜力。未来,随着技术的进步与研究的深入,NSM方法不仅将在移民研究中继续发挥重要作用,还将为其他社会群体的研究提供新的可能性。
本研究对NSM方法在加拿大华人移民调查中的应用进行了系统论证,并通过对社交网络的逐步揭示,解决了传统采样方法中的多个难题。未来,随着人工智能、数据分析技术的结合与跨国研究的拓展,NSM方法的应用领域将进一步扩大,不仅限于移民研究,还将扩展至其他难以接触的隐性群体研究,如难民、无家可归者、非法劳工等。
此外,NSM方法的多维度分析能力将继续优化,通过结合不同社会网络层次、职业网络与社区关系的交叉分析,未来的研究有望揭示更为复杂的群体互动与动态。随着社交网络分析工具和大数据技术的发展,NSM的采样效率、数据处理能力以及样本质量都将进一步提升。
总而言之,NSM方法不仅为社会科学研究带来了新的视角与工具,还在全球化和复杂社会结构背景下,为隐性群体的研究提供了更加准确和广泛的数据支持。未来,通过进一步优化该方法的操作流程、结合更多的技术创新,NSM将有能力成为社会研究中标准化的采样工具,为政策制定者和学术界提供深刻的洞察与数据支持。
参考文献
[1]Agans R P, Zeng D, Shook-Sa B E, et al. Using social networks to supplement RDD telephone surveys to oversample hard-to-reach populations: a new RDD+ RDS approach[J]. Sociological methodology, 2021, 51(2): 270-289.
[2]Avin C, Krishnamachari B. The power of choice in random walks: An empirical study[J]. Computer Networks, 2008, 52(1): 44-60.
[3]Beauchemin C, Hamel C, Simon P. Trajectoires et origines: enquête sur la diversité des populations en France[M]. Ined éditions, 2016.
[4]Lu X. Respondent-driven sampling: theory, limitations & improvements[M]. Karolinska Institutet (Sweden), 2013.
[5]Marpsat M, Razafindratsima N. Les méthodes d'enquêtes auprès des populations difficiles à joindre: Introduction au numéro spécial[J]. Methodological Innovations Online, 2010, 5(2): 3-16.
[6]Mercer S. Social network analysis and complex dynamic systems[J]. Motivational dynamics in language learning, 2015: 73-82.
[7]Mouw T, Verdery A M. Network sampling with memory: a proposal for more efficient sampling from social networks[J]. Sociological methodology, 2012, 42(1): 206-256.
[8]Portes A, Rumbaut R G. Immigrant America: a portrait[M]. Univ of California Press, 2024.
[9]Salganik M J. Bit by bit: Social research in the digital age[M]. Princeton University Press, 2019.
[10]Santos A, Charrance G. From theory to practice: Lessons learned from implementing the network sampling with memory method[C]//Proceedings of Statistics Canada Symposium 2022: Data Disaggregation: Building a More Representative Data Portrait of Society. Statistics Canada, 2024.
[11]Schiltz M A. Faire et défaire des groupes: l’information chiffrée sur les «populations difficiles à atteindre»[J]. Bulletin de méthodologie sociologique. Bulletin of sociological methodology, 2005 (86): 30-54.
[12]Statistics Canada. 2021 Census of population [EB/OL]. Government of Canada, [2024-09-05]. https://www12.statcan.gc.ca/census-recensement/2021/dp-pd/index-eng.cfm.
作者信息(Author Biography):孙鹏(1982.10),博士,加拿大籍华人学者,研华学思特聘专家,专注于跨文化与全球化、文化与社会、人口与移民以及人才与教育等领域研究。他的研究兴趣广泛且深入,涵盖了企业跨文化管理、全球化进程对企业和社会的影响、多元文化背景下的文化融合与冲突、国际移民与人口流动、国际人才交流以及华人社群和留学生问题等方面。孙鹏致力于探索企业在全球化背景下如何实现有效的跨文化管理,研究文化在全球化进程中的传播与变迁,以及移民和人口流动对全球社会经济的影响。同时,他也关注数字化转型、技术创新与创业、环境保护与可持续发展等新兴研究领域,力求通过多学科的视角,为社会和经济的未来发展提供有力的理论支持和实践指导。



